Как Cisco мониторит безопасность в своей внутренней сети
С точки зрения обеспечения кибербезопасности перед нами обычно стоит всего три основные задачи, которые, конечно, потом разбиваются на более мелкие подзадачи и проекты, но, немного утрируя, по-крупному, задач всего три:
- Предотвращение угроз
- Обнаружение угроз
- Реагирование на угрозы.
Зачем нужно мониторить внутреннюю сеть?
Какие бы решения мы не рассматривали они укладываются в эти три задачи, которые мы должны реализовывать в любом месте корпоративной сети. Вот этот жизненный цикл борьбы с угрозами (ДО — ВО ВРЕМЯ — ПОСЛЕ) и положен в основу деятельности службы ИБ компании Cisco. Причем обращу внимание, что так как в компании Cisco отсутствует понятие периметра, то мы стараемся реализовать описанные выше три задачи везде — в ЦОДах, в облаках, в сегменте Wi-Fi, на мобильных устройствах сотрудников, в точках выхода в Интернет и, конечно же, в нашей внутренней сети, о мониторинге которой мы сегодня и поговорим.
У нас ведь такой вопрос не возникает относительно периметра (почему у нас нет периметра, я расскажу как-нибудь в другой раз), где мы ставим и МСЭ, и IDS, и средства контентной фильтрации, множество других средств сетевой безопасности. Почему же внутренняя сеть должна быть исключением? Что, в нее нельзя попасть извне, минуя периметр? Да кучей способов. Через незащищенный собственный Wi-Fi или через точку доступа соседней “Шоколадницы”, к которой автоматически подключаются мобильные устройства ваших сотрудников, привыкших в кафе перехватить чашку горячего кофе или пообедать. Через взломанный домашний ноутбук или планшет/смартфон руководства, которое притащило его в офис, чтобы “айтишники разобрались”. Через подброшенную к офису флешку, на которой залит нетектируемый вредоносный код. Через зашифрованный канал клиент-серверного приложения, которое разрабатывали без учетов вопросов безопасности. Да через уязвимости в периметр в конце концов (не будем же мы считать, что наш МСЭ абсолютно неуязвим). То есть внутренняя сеть нуждается в такой же защите, как и периметр, на котором многие организации неоправданно часто фокусируют свои усилия по защите, напрочь забывая про истину о самом слабом звене.
Разве IDS недостаточно?
Как предотвращаются угрозы во внутренней сети Cisco я уже рассказыва — мы используем для этого Cisco Identity Service Engine (ISE), который выполняет функцию распределенного МСЭ, превращающего каждый коммутатор или маршрутизатор, а у нас только последних свыше 40 тысяч, в часть внутреннего средства разграничения доступа, работающего на динамических политиках. Но одного разграничения и предотвращения нам недостаточно. Мы должны также контролировать активность в рамках разрешенных внутри соединений, а также отслеживать любые нарушения установленных правил внутреннего доступа (все мы люди, всем нам свойственно ошибаться). На периметре бы мы поставили систему обнаружения вторжений (IDS) и решили бы эту проблему. Во внутренней сети ставить IDS непросто, хотя Cisco была бы рада продать как можно больше сенсоров нашей Cisco NGIPS, тем более что мы в очередной раз стали лидером этого рынка по версии Gartner. Но это зачастую невозможно (исключая некоторые места внутри сети типа ЦОДов или отдельных сегментов). Невозможно и с точки зрения архитектуры — не на каждый порт коммутатора можно поставить сенсор IDS, не каждый транковый или span-порт, к которому часто подключается IDS, потянет трафик со всех портов коммутатора, не всегда span-порт свободен. Невозможно и с точки зрения финансов — очень уж дорого покупать высокопроизводительные сенсоры на каждый коммутатор или маршрутизатор. Даже в Cisco, несмотря на то, что мы сами и производим NGIPS, мы не можем тратить немалые средства на мониторинг с помощью IDS нашей внутренней сети — это достаточно накладно. Даже если попробовать применить разветвители (tap), то они не решат всех проблем ни с точки зрения архитектуры, ни с точки зрения финансов. Кроме того, если на периметре безопасники еще как-то научились жить с айтишниками (сетевиками), то во внутренней сети конфликт продолжает тлеть. Есть ли у нас альтернатива классическим сетевым IDS для решения той же задачи?
Как мониторить внутреннюю сеть без IDS?
Ответ будет положительным и зовется он Netflow. Это протокол, который был первоначально разработан компанией Cisco для целей обнаружения проблем в сети (troobleshooting), который затем стал стандартом де-факто для многих сетевых производителей, которые либо поддерживали в своем оборудовании Netflow, либо создавали его клоны — Cflow, sFlow, Jflow, NetStream, Rflow и т.п. Но поскольку мы сегодня говорим о том, как мониторится внутренняя сеть Cisco, а у нас используется наше же сетевое оборудование, то мы сконцентрируемся только на протоколе Netflow, который есть сегодня почти на любой нормальной сетевой “железке” корпоративного уровня (от всяких “домашних” устройств ждать поддержки Netflow не стоит — дома она просто не нужна и только утяжелит и удорожит решение).
Итак, Netflow на сетевом оборудовании, через которое проходит весь трафик, требующий контроля, есть. Это значит, что мы можем попробовать использовать его не только для обнаружения каких-либо проблем в сети, но и для целей информационной безопасности. Кроме того, поддержка Netflow сетевым оборудованием позволяет нам не строить отдельную, наложенную сеть для целей мониторинга, а позволяет уже используемое сетевое оборудование задействовать и под задачи ИБ. Это с одной стороны защищает уже сделанные инвестиции и удешевляет решение по мониторингу, а с другой, делает его более простым с точки зрения и архитектуры и внедрения — не надо пытаться правильно направить нужные нам потоки на десятки или сотни сенсоров IDS, которые в противоположном случае мы бы вынуждены были поставить в своей сети. Работа с Netflow дает нам и еще одно, не сразу видимое преимущество. В случае с установкой обычных IDS мы должны решить задачу направления трафика или его копии на сенсоры системы защиты. Если по каким-то причинам этого не произойдет (например, по причине смены топологии или нехватка пропускной способности у сенсора), то мы ровном счетом ничего не увидим и будем думать, что никаких атак в интересующем нас трафике нет. Сам сенсор же работает — только не получает и не анализирует нужный трафик. С Netflow это не проходит — мы видим все, что протекает через сетевое устройство, в качестве которого может выступать не только маршрутизатор или коммутатор (в том числе и виртуальные), но и, например, межсетевой экран (например, Cisco ASA поддерживает функцию NSEL, Netflow Security Event Logging, которая позволяет транслировать сетевые потоки в виде Netflow для анализа соответствующим средством мониторинга).
Пора сделать пару замечаний относительно Netflow, которые получили в результате эксплуатации Netflow для целей безопасности в сети Cisco. Во-первых, надо знать, что Netflow бывает несемплированный и семплированный. Отличия между ними такие же, как если читать полную книгу “от корки до корки” или пролистывать ее, останавливаясь только на каждой десятой странице. Многие сетевые устройства поддерживают Netflow, но только семплированный, который не подходит для целей безопасности, так как мы видим только малую часть всего трафика, который нам нужен для мониторинга. Поэтому обращайте внимание на то, какой Netflow у вас поддерживается. Семплированный для целей ИБ не подходит. Во-вторых, надо знать, что обработка Netflow, особенно несемплированного создает нагрузку на процессор сетевого устройства, что необходимо учитывать при планировании сети и выстраивании системы мониторинга ИБ на базе Netflow. Если ваши коммутаторы или маршрутизаторы работают уже на пределе своих сил и загрузка их ЦПУ достигает 80-90% в обычном режиме работе, то стоит десять раз подумать, включать ли на них Netflow, из-за которго производительность устройство точно просядет еще больше. Решений в данной ситуации два — обновление сетевой инфраструктуры (все равно рано или поздно это пришлось бы делать) и использование устройств генерации Netflow. Мы в Cisco использовали оба варианта. В тех случаях, где мониторинг Netflow был критичной задачей и пришло время для апгрейда, мы установили новые коммутаторы и марщратизаторы с аппаратной обработкой Netflow, ненагружающее ЦПУ. В других случаях мы воспользовались решением под названием FlowSensor, которое пропускаемый через себя трафик (аналог разветвителя, tap) транслировало в Netflow, передаваемый дальше для анализа нашей службой безопасности.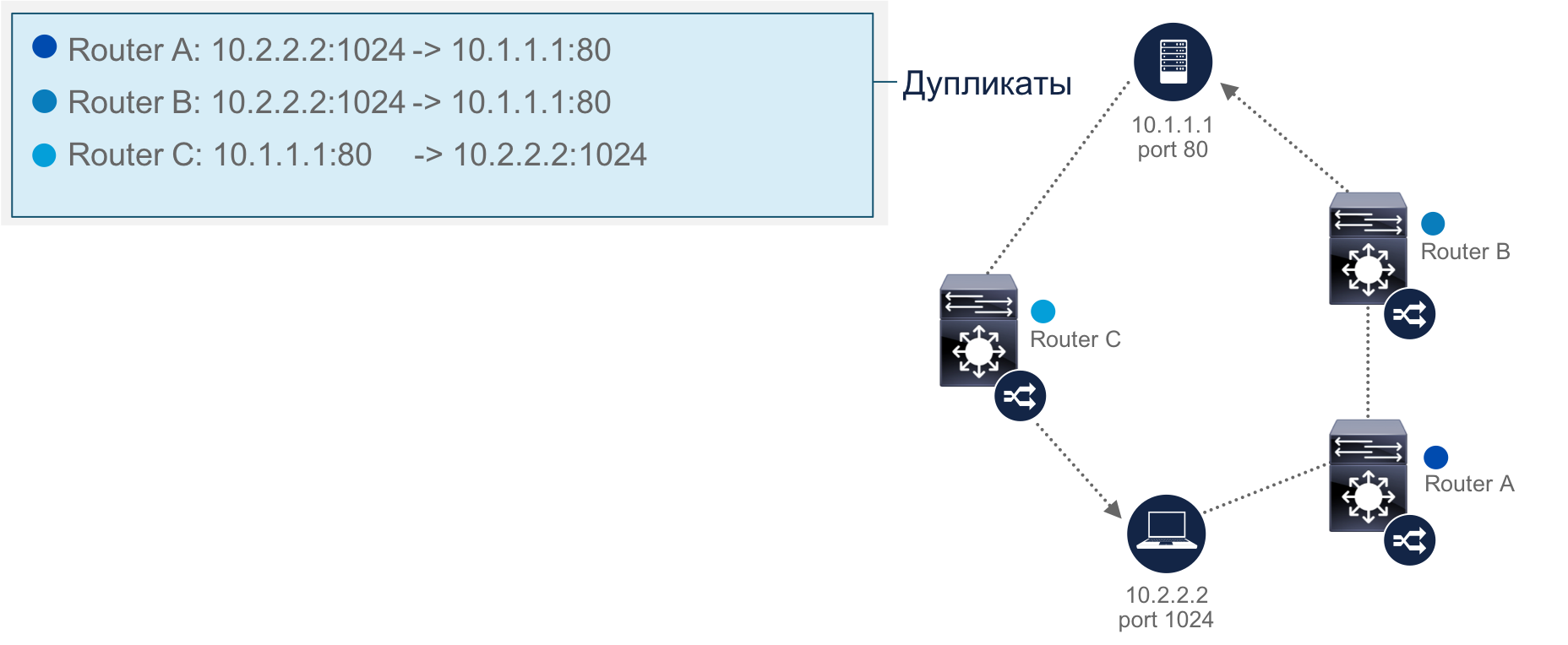
Еще одной проблемой применения nfdump и OSU Flow Tools является неумение распознавать, кто инициировал то или иное соединение (это важно при расследовании), так как потоки однонаправленные. Приходится проводить допонительную работу для того, чтобы понять, кто был первым в клиент-серверных соединениях. Наконец, мы наткнулись и еще на одну тонкость, связанную с работой названных утилит. Они записывают только завершенные потоки, что может привести к невозможности оперативно отследить атаки, происходящие в реальном времени. Например, злоумышленник уже провел сканирование сети, компрометацию узла и проникновение на него, а ни nfdump, ни Flow Tools еще об этом не знают, так как сетевой поток ими не зафиксирован.
Что мы используем сейчас?
После полученного опыта работы с nfdump и OSU Flow Tools и по мере перехода на IPv6 и Netflow 9-й версии мы стали искать инструмент, лишенный недостатков, с которыми мы столкнулись. Им стало решение Stealthwatch компании Lancope, которую мы позже приобрели и она стала частью Cisco. Stealthwatch построен по классической для любого анализатора архитектуре “сенсор — коллектор — анализатор”.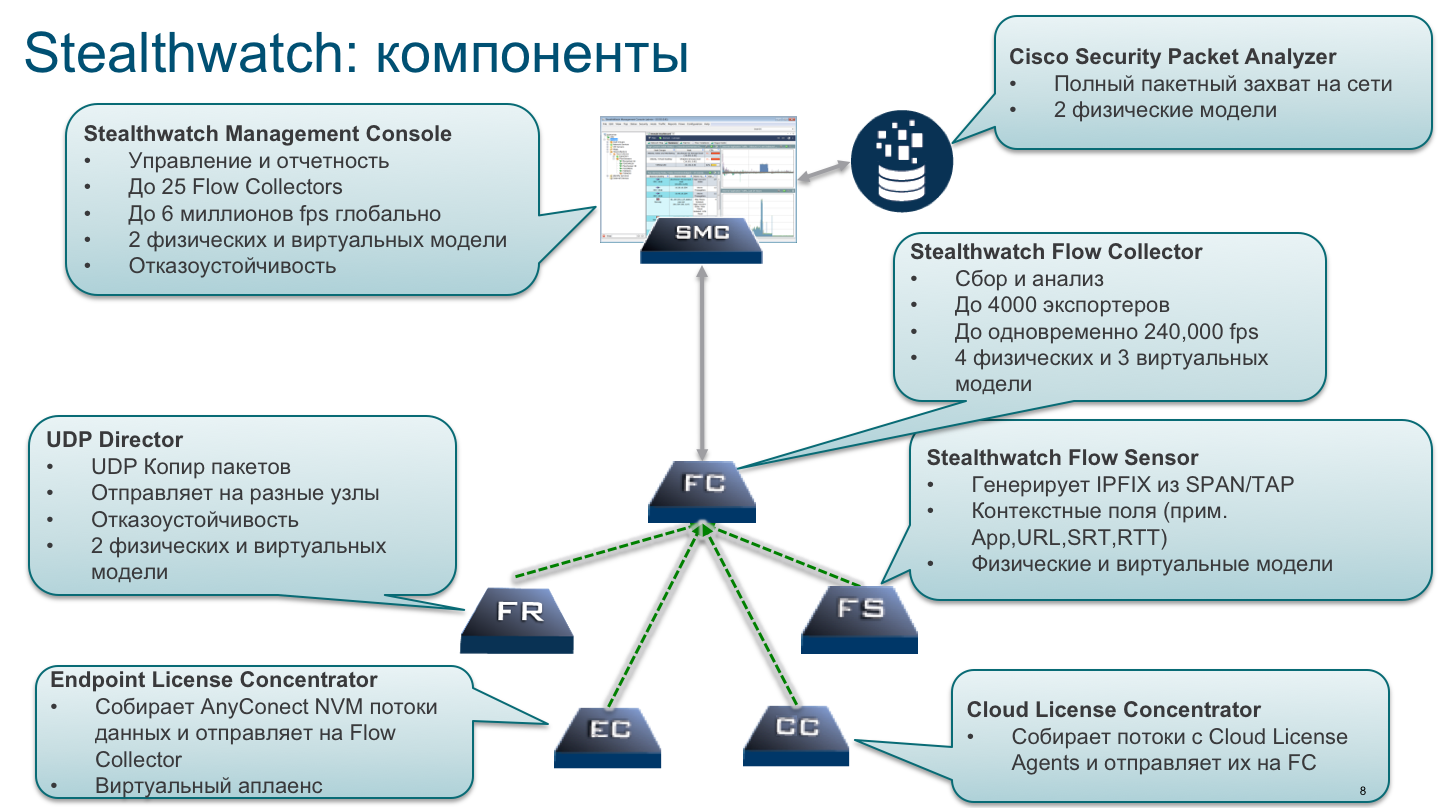
В качестве сенсоров мы используем нашу сетевую инфраструктуру, которая пропуская через себя весь внутренний сетевой трафик, транслирует его в Netflow и передает на коллекторы для анализа. Как я уже писал выше, не всегда сетевое оборудование поддерживает Netflow или способно его эффективно обрабатывать. Для этой задачи мы используем отдельные аппаратные или виртуальные FlowSensor (всего их у нас 13). Учитывая территориально-распределенную инфраструктуру Cisco мы сводим все потоки не на один или два коллектора, а целый распределенный кластер из 21 FlowCollector, которые обрабатывают около 20 миллиардов потоков Netflow каждый день в поисках вредоносной активности в нашей корпоративной магистрали и ЦОДах. А консолей у нас всего две — к ним имеют доступ сотрудники службы реагирования на инциденты Cisco в соответствие со своими ролями.
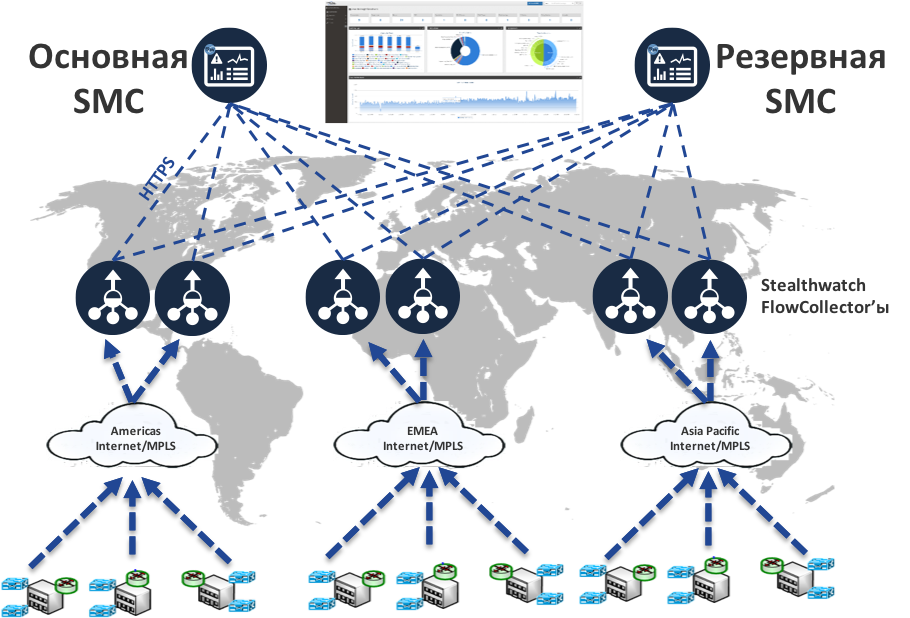
Кто и где использует Stealthwatch?
Stealthwatch является решением, которое хотя и может применяться сетевиками и айтишниками, но предназначено для безопасников. В Cisco им занимается служба реагирования на инциденты Cisco CSIRT. Мы собираем данные с 180 ключевых сетевых устройств, установленных в центрах обработки данных, крупных корпоративных хабах и в DMZ, получая примерно 180 тысяч потоков в секунду.
В одной из прошлых заметок я уже писал о наличии API в наших продуктах. Такой API есть и в Stealthwatch и он очень активно используется нашей службой реагирования на инциденты. В частности именно через API мы обновляем информацию об узлах, включеннх в те или иные группы.
Именно через API мы обновляем информацию о новых вредоносных узлах, взаимодействие с которыми отслеживается с помощью Stealthwatch. С помощью API мы интегрируем Stealthwatch с используемой у нас open source платформой Threat Intelligence CRiTS. Это позволяет нам при получении данных о новых индикаторах компрометации раздать эту информацию по всем средствам защиты, интегрированным с CRiTS через API.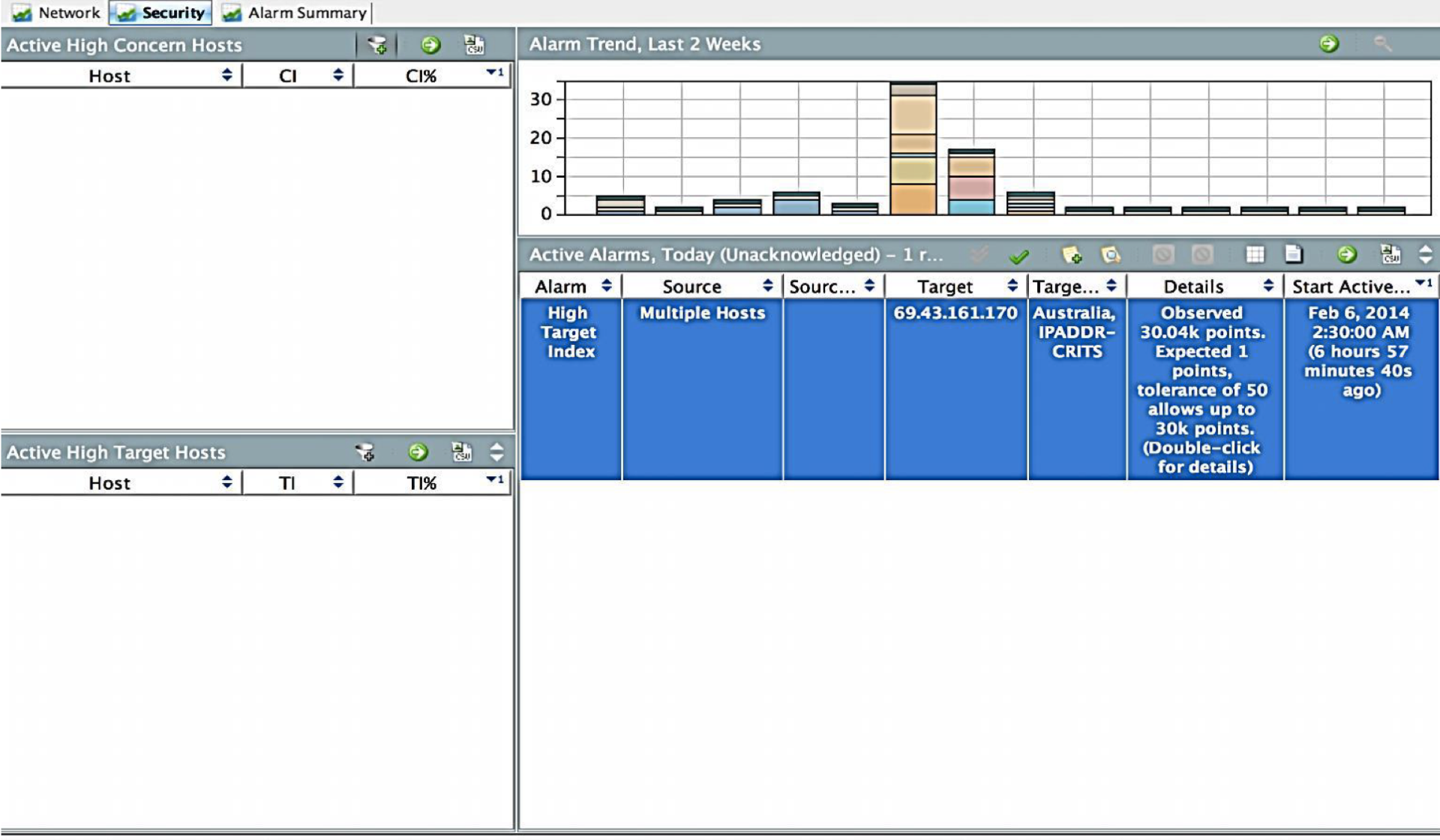
API же позволяет собирать из Stealthwatch нужные нам события и потоки для передачи их в Splunk, который является основным средством мониторинга в Cisco, в том числе и для проведения более детальных расследований.
Интересным опытом, который я пока больше нигде не встречал, является концепция мобильного SOC (Security Operations Center), который мы используем для мониторинга ИБ на удаленных площадках, покупаемых нами компаний, новых заводах, партнерах или при проведении расследований на площадках, которые не подключены на центральную систему мониторинга. Мобильный SOC — это перевозимая стойка с ИБ-оборудованием, которое включает в себя не только Stealthwatch, но и Netflow Generation Appliance, Splunk, Firepower, Web Security Appliance и т.п.
Планы развития
Мы не останавливаемая на достигнутом и планируем достаточно активно развивать применение Stealthwatch в нашей инфраструктуре. Среди первоочередных планов:
- Продолжение интеграции с ISE не только для получения контекстной информации об узлах и пользователях, участвующих в инциденте, но и для реализации функции блокирования. В перспективе через ISE должна быть реализована связка Stealthwatch на уровне сети и AMP4E на уровне ПК, что позволит оперативнее локализовывать проблемы с ИБ.
- По мере перехода на новую версию Stealthwatch автоматически появится функций Encrypted Traffic Analytics, позволяющая детектировать вредоносный код в зашифрованном трафике.
- Внедрение Stealthwatch Cloud для мониторинга облачных платформ IaaS и PaaS, которые активно используются в Cisco.
- Интеграция с AnyConnect, который внедрен у каждого сотрудника Cisco на его ноутбуке, смартфоне или лэптопе, для того, что получать данные об активности пользователей и приложений в формате Netflow и корреляции этой информации с Netflow на сетевом уровне.




